HOTSPOT -
You have an Azure Data Factory instance named ADF1 and two Azure Synapse Analytics workspaces named WS1 and WS2.
ADF1 contains the following pipelines:
✑ P1: Uses a copy activity to copy data from a nonpartitioned table in a dedicated SQL pool of WS1 to an Azure Data Lake Storage Gen2 account
✑ P2: Uses a copy activity to copy data from text-delimited files in an Azure Data Lake Storage Gen2 account to a nonpartitioned table in a dedicated SQL pool of WS2
You need to configure P1 and P2 to maximize parallelism and performance.
Which dataset settings should you configure for the copy activity of each pipeline? To answer, select the appropriate options in the answer area.
Hot Area:
Answer:

P1: Set the Partition option to Dynamic Range.
The SQL Server connector in copy activity provides built-in data partitioning to copy data in parallel.
P2: Set the Copy method to PolyBase
Polybase is the most efficient way to move data into Azure Synapse Analytics. Use the staging blob feature to achieve high load speeds from all types of data stores, including Azure Blob storage and Data Lake Store. (Polybase supports Azure Blob storage and Azure Data Lake Store by default.)
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-sql-data-warehouse https://docs.microsoft.com/en-us/azure/data-factory/load-azure-sql-data-warehouse
You have the following Azure Data Factory pipelines:
✑ Ingest Data from System1
Ingest Data from System2 -
✑ Populate Dimensions
✑ Populate Facts
Ingest Data from System1 and Ingest Data from System2 have no dependencies. Populate Dimensions must execute after Ingest Data from System1 and Ingest
Data from System2. Populate Facts must execute after the Populate Dimensions pipeline. All the pipelines must execute every eight hours.
What should you do to schedule the pipelines for execution?
Answer:
D
Reference:
https://www.mssqltips.com/sqlservertip/6137/azure-data-factory-control-flow-activities-overview/
You have an Azure Data Factory pipeline that performs an incremental load of source data to an Azure Data Lake Storage Gen2 account.
Data to be loaded is identified by a column named LastUpdatedDate in the source table.
You plan to execute the pipeline every four hours.
You need to ensure that the pipeline execution meets the following requirements:
✑ Automatically retries the execution when the pipeline run fails due to concurrency or throttling limits.
✑ Supports backfilling existing data in the table.
Which type of trigger should you use?
Answer:
A
The Tumbling window trigger supports backfill scenarios. Pipeline runs can be scheduled for windows in the past.
Incorrect Answers:
D: Schedule trigger does not support backfill scenarios. Pipeline runs can be executed only on time periods from the current time and the future.
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/concepts-pipeline-execution-triggers
You have an Azure Data Factory that contains 10 pipelines.
You need to label each pipeline with its main purpose of either ingest, transform, or load. The labels must be available for grouping and filtering when using the monitoring experience in Data Factory.
What should you add to each pipeline?
Answer:
A
Azure Data Factory annotations help you easily filter different Azure Data Factory objects based on a tag. You can define tags so you can see their performance or find errors faster.
Reference:
https://www.techtalkcorner.com/monitor-azure-data-factory-annotations/
HOTSPOT -
You have an Azure data factory that has two pipelines named PipelineA and PipelineB.
PipelineA has four activities as shown in the following exhibit.
PipelineB has two activities as shown in the following exhibit.
You create an alert for the data factory that uses Failed pipeline runs metrics for both pipelines and all failure types. The metric has the following settings:
✑ Operator: Greater than
✑ Aggregation type: Total
✑ Threshold value: 2
✑ Aggregation granularity (Period): 5 minutes
✑ Frequency of evaluation: Every 5 minutes
Data Factory monitoring records the failures shown in the following table.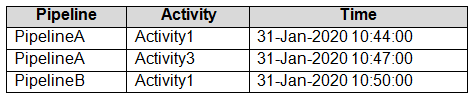
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:

Box 1: No -
Just one failure within the 5-minute interval.
Box 2: No -
Just two failures within the 5-minute interval.
Box 3: No -
Just two failures within the 5-minute interval.
Reference:
https://docs.microsoft.com/en-us/azure/azure-monitor/alerts/alerts-metric-overview
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Data Lake Storage account that contains a staging zone.
You need to design a daily process to ingest incremental data from the staging zone, transform the data by executing an R script, and then insert the transformed data into a data warehouse in Azure Synapse Analytics.
Solution: You use an Azure Data Factory schedule trigger to execute a pipeline that executes mapping data flow, and then inserts the data into the data warehouse.
Does this meet the goal?
Answer:
B
Correct solution: You use an Azure Data Factory schedule trigger to execute a pipeline that executes an Azure Databricks notebook, and then inserts the data into the data warehouse.
Reference:
https://docs.microsoft.com/en-US/azure/data-factory/transform-data
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Data Lake Storage account that contains a staging zone.
You need to design a daily process to ingest incremental data from the staging zone, transform the data by executing an R script, and then insert the transformed data into a data warehouse in Azure Synapse Analytics.
Solution: You schedule an Azure Databricks job that executes an R notebook, and then inserts the data into the data warehouse.
Does this meet the goal?
Answer:
B
Must use an Azure Data Factory, not an Azure Databricks job.
Correct solution: You use an Azure Data Factory schedule trigger to execute a pipeline that executes an Azure Databricks notebook, and then inserts the data into the data warehouse.
Reference:
https://docs.microsoft.com/en-US/azure/data-factory/transform-data
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Data Lake Storage account that contains a staging zone.
You need to design a daily process to ingest incremental data from the staging zone, transform the data by executing an R script, and then insert the transformed data into a data warehouse in Azure Synapse Analytics.
Solution: You use an Azure Data Factory schedule trigger to execute a pipeline that executes an Azure Databricks notebook, and then inserts the data into the data warehouse.
Does this meet the goal?
Answer:
A
An Azure Data Factory can trigger a Databricks notebook.
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/transform-data-using-databricks-notebook
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Data Lake Storage account that contains a staging zone.
You need to design a daily process to ingest incremental data from the staging zone, transform the data by executing an R script, and then insert the transformed data into a data warehouse in Azure Synapse Analytics.
Solution: You use an Azure Data Factory schedule trigger to execute a pipeline that copies the data to a staging table in the data warehouse, and then uses a stored procedure to execute the R script.
Does this meet the goal?
Answer:
B
Azure Synapse Analytics does not support R script.
Correct solution: You use an Azure Data Factory schedule trigger to execute a pipeline that executes an Azure Databricks notebook, and then inserts the data into the data warehouse.
Reference:
https://docs.microsoft.com/en-us/azure/architecture/data-guide/technology-choices/r-developers-guide
DRAG DROP -
You have an Azure subscription that contains an Azure SQL managed instance named SQLMi1 and a SQL Agent job named Backupdb. Backupdb performs a daily backup of the databases hosted on SQLMi1.
You need to be notified by email if the job fails.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.
Select and Place:
Answer:
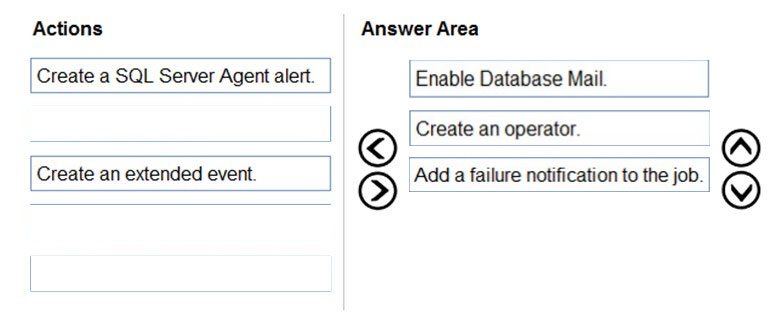
Step 1: Enable Database Mail -
If it isn't already enabled, first you would need to configure the Database Mail feature on SQL Managed Instance.
Box 2: Create an operator.
You can notify the operator that something happened with your SQL Agent jobs. An operator defines contact information for an individual responsible for the maintenance of one or more instances in SQL Managed Instance.
Box 3: Add a failure notification to the job,
You can then modify any SQL Agent job and assign operators that will be notified via email if the job completes, fails, or succeeds using SSMS or the following T-
SQL script:
EXEC msdb.dbo.sp_update_job @job_name=N'Load data using SSIS',
@notify_level_email=3, -- Options are: 1 on succeed, 2 on failure, 3 on complete
@notify_email_operator_name=N'AzureSQLTeam';
Reference:
https://docs.microsoft.com/en-us/azure/azure-sql/managed-instance/job-automation-managed-instance