You have a database in an Azure Cosmos DB Core (SQL) API account. The database is backed up every two hours.
You need to implement a solution that supports point-in-time restore.
What should you do first?
Answer:
A
When creating a new Azure Cosmos DB account, in the Backup policy tab, choose continuous mode to enable the point in time restore functionality for the new account. With the point-in-time restore, data is restored to a new account, currently you can't restore to an existing account.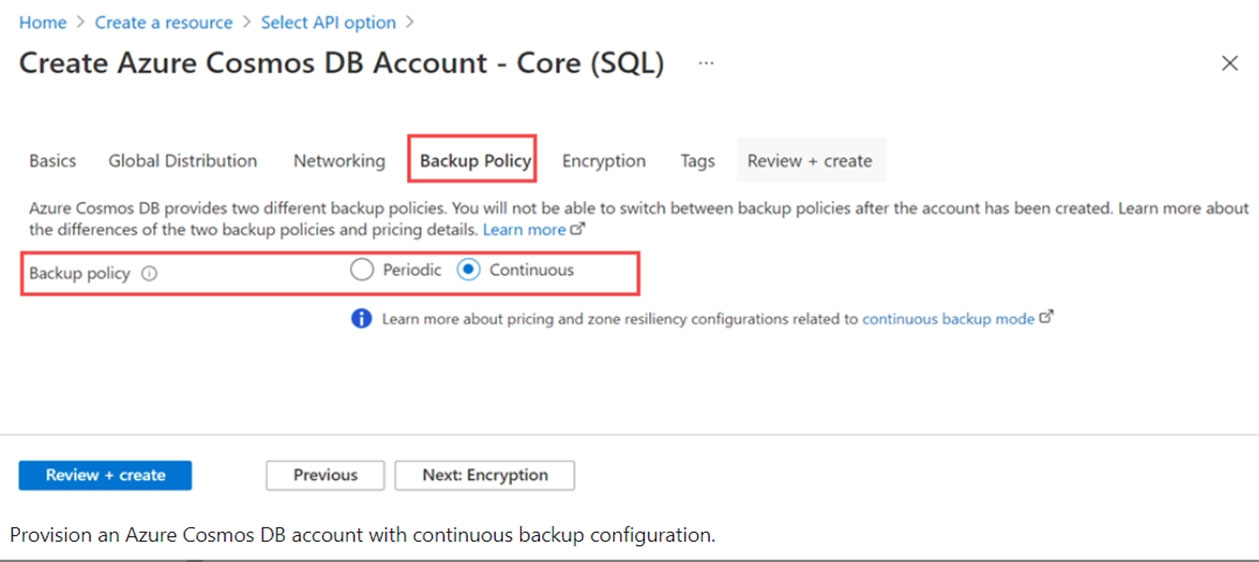
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/provision-account-continuous-backup
HOTSPOT -
You have an Azure Cosmos DB Core (SQL) API account used by an application named App1.
You open the Insights pane for the account and see the following chart.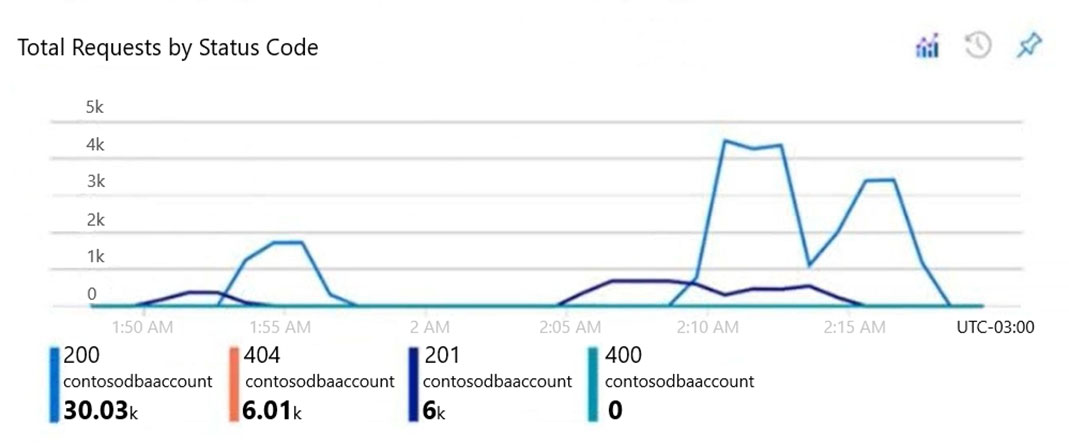
Use the drop-down menus to select the answer choice that answers each question based on the information presented in the graphic.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:

Box 1: incorrect connection URLs
400 Bad Request: Returned when there is an error in the request URI, headers, or body. The response body will contain an error message explaining what the specific problem is.
The HyperText Transfer Protocol (HTTP) 400 Bad Request response status code indicates that the server cannot or will not process the request due to something that is perceived to be a client error (for example, malformed request syntax, invalid request message framing, or deceptive request routing).
Box 2: 6 thousand -
201 Created: Success on PUT or POST. Object created or updated successfully.
Note:
200 OK: Success on GET, PUT, or POST. Returned for a successful response.
404 Not Found: Returned when a resource does not exist on the server. If you are managing or querying an index, check the syntax and verify the index name is specified correctly.
Reference:
https://docs.microsoft.com/en-us/rest/api/searchservice/http-status-codes
You have a database in an Azure Cosmos DB Core (SQL) API account.
You need to create an Azure function that will access the database to retrieve records based on a variable named accountnumber. The solution must protect against SQL injection attacks.
How should you define the command statement in the function?
Answer:
C
Azure Cosmos DB supports queries with parameters expressed by the familiar @ notation. Parameterized SQL provides robust handling and escaping of user input, and prevents accidental exposure of data through SQL injection.
For example, you can write a query that takes lastName and address.state as parameters, and execute it for various values of lastName and address.state based on user input.
SELECT *
FROM Families f -
WHERE f.lastName = @lastName AND f.address.state = @addressState
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/sql/sql-query-parameterized-queries
HOTSPOT -
You plan to deploy two Azure Cosmos DB Core (SQL) API accounts that will each contain a single database. The accounts will be configured as shown in the following table.
How should you provision the containers within each account to minimize costs? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:

Box 1: Serverless capacity mode -
Azure Cosmos DB serverless best fits scenarios where you expect intermittent and unpredictable traffic with long idle times. Because provisioning capacity in such situations isn't required and may be cost-prohibitive, Azure Cosmos DB serverless should be considered in the following use-cases:
✑ Getting started with Azure Cosmos DB
✑ Running applications with bursty, intermittent traffic that is hard to forecast, or low (<10%) average-to-peak traffic ratio
✑ Developing, testing, prototyping and running in production new applications where the traffic pattern is unknown
✑ Integrating with serverless compute services like Azure Functions
Box 2: Provisioned throughput capacity mode and autoscale throughput
The use cases of autoscale include:
✑ Variable or unpredictable workloads: When your workloads have variable or unpredictable spikes in usage, autoscale helps by automatically scaling up and down based on usage. Examples include retail websites that have different traffic patterns depending on seasonality; IOT workloads that have spikes at various times during the day; line of business applications that see peak usage a few times a month or year, and more. With autoscale, you no longer need to manually provision for peak or average capacity.
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/serverless
https://docs.microsoft.com/en-us/azure/cosmos-db/provision-throughput-autoscale#use-cases-of-autoscale
HOTSPOT -
You have a container named container1 in an Azure Cosmos DB Core (SQL) API account. The container1 container has 120 GB of data.
The following is a sample of a document in container1.
The orderId property is used as the partition key.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:

Box 1: Yes -
Records with different OrderIDs will match.
Box 2: Yes -
Records with different OrderIDs will match.
Box 3: No -
Only records with one specific OrderId will match
You are designing an Azure Cosmos DB Core (SQL) API solution to store data from IoT devices. Writes from the devices will be occur every second.
The following is a sample of the data.
You need to select a partition key that meets the following requirements for writes:
✑ Minimizes the partition skew
✑ Avoids capacity limits
✑ Avoids hot partitions
What should you do?
Answer:
D
Use a partition key with a random suffix. Distribute the workload more evenly is to append a random number at the end of the partition key value. When you distribute items in this way, you can perform parallel write operations across partitions.
Incorrect Answers:
A: You will also not like to partition the data on ג€DateTimeג€, because this will create a hot partition. Imagine you have partitioned the data on time, then for a given minute, all the calls will hit one partition. If you need to retrieve the data for a customer, then it will be a fan-out query because data may be distributed on all the partitions.
B: Senser1Value has only two values.
C: All the devices could have the same manufacturer.
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/sql/synthetic-partition-keys
You maintain a relational database for a book publisher. The database contains the following tables.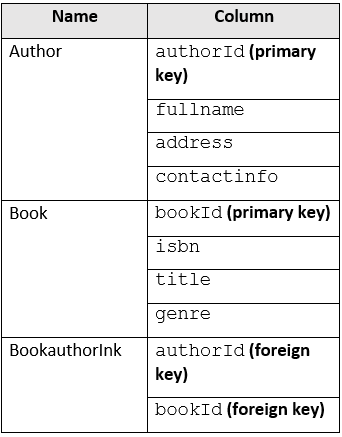
The most common query lists the books for a given authorId.
You need to develop a non-relational data model for Azure Cosmos DB Core (SQL) API that will replace the relational database. The solution must minimize latency and read operation costs.
What should you include in the solution?
Answer:
A
Store multiple entity types in the same container.
You have an Azure Cosmos DB Core (SQL) API account.
You run the following query against a container in the account.
What is the output of the query?
Answer:
A
IS_NUMBER returns a Boolean value indicating if the type of the specified expression is a number.
"1234" is a string, not a number.
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/sql/sql-query-is-number
HOTSPOT -
You have an Azure Cosmos DB Core (SQL) API account named account1.
In account1, you run the following query in a container that contains 100GB of data.
You view the following metrics while performing the query.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:

Box 1: No -
Each physical partition should have its own index, but since no index is used, the query is not cross-partition.
Box 2: No -
Index utilization is 0% and Index Look up time is also zero.
Box 3: Yes -
A partition key index will be created, and the query will perform across the partitions.
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/sql/how-to-query-container
You have an Azure Cosmos DB Core (SQL) API account that is used by 10 web apps.
You need to analyze the data stored in the account by using Apache Spark to create machine learning models. The solution must NOT affect the performance of the web apps.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
Answer:
AD
Explore analytical store with Apache Spark
1. Navigate to the Data hub.
2. Select the Linked tab (1), expand the Azure Cosmos DB group (if you don't see this, select the Refresh button above), then expand the WoodgroveCosmosDb account (2). Right-click on the transactions container (3), select New notebook (4), then select Load to DataFrame (5).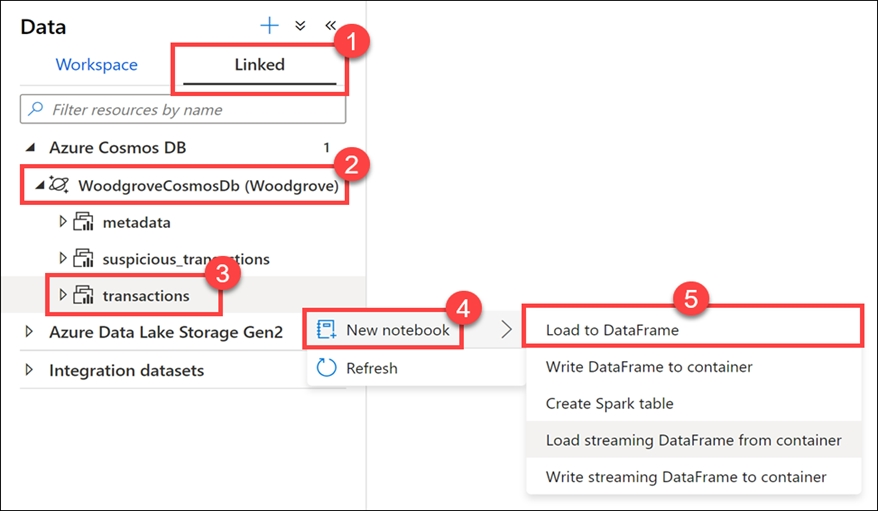
3. In the generated code within Cell 1 (3), notice that the spark.read format is set to cosmos.olap. This instructs Synapse Link to use the container's analytical store. If we wanted to connect to the transactional store, like to read from the change feed or write to the container, we'd use cosmos.oltp instead.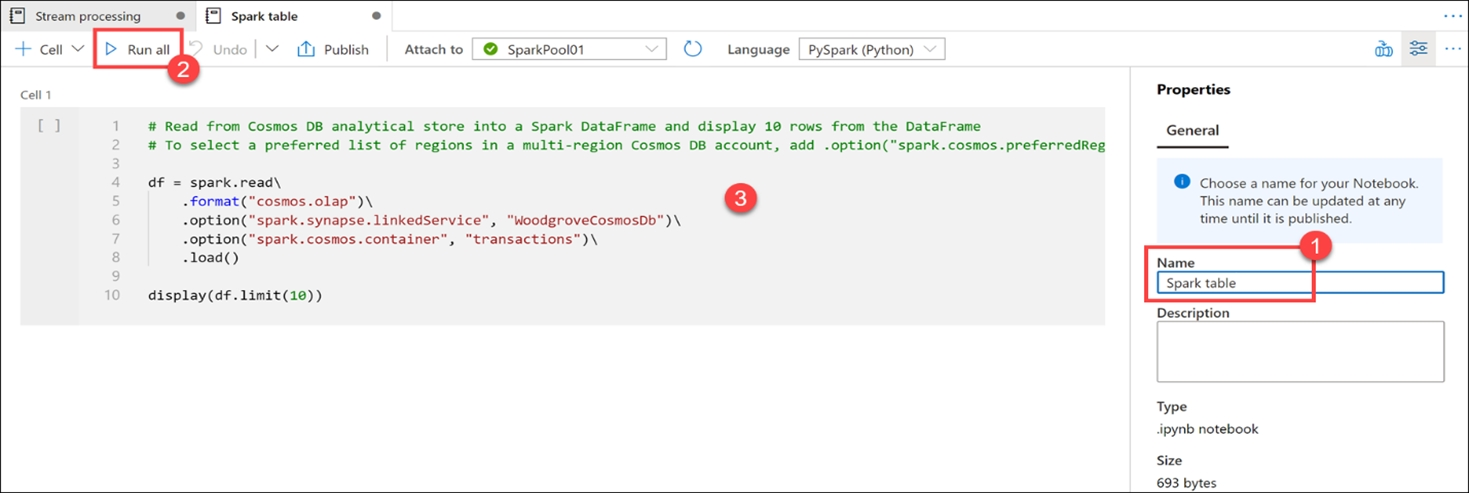
Reference:
https://github.com/microsoft/MCW-Cosmos-DB-Real-Time-Advanced-Analytics/blob/main/Hands-on%20lab/HOL%20step-by%20step%20-%20Cosmos%20DB%
20real-time%20advanced%20analytics.md