You have an Azure Cosmos DB Core (SQL) API account that has multiple write regions.
You need to receive an alert when requests that target the database exceed the available request units per second (RU/s).
Which Azure Monitor signal should you use?
Answer:
B
Use an alert which is triggered when the container or a database has exceeded the provisioned throughput limit.
Note: Provisioned throughput is the maximum amount of capacity that an application can consume from a table or index. If your application exceeds your provisioned throughput capacity on a table or index, it is subject to request throttling. Throttling prevents your application from consuming too many capacity units.
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/monitor-cosmos-db
HOTSPOT -
You have a database named db1 in an Azure Cosmos DR Core (SQL) API account named account1. The db1 database has a manual throughput of 4,000 request units per second (RU/s).
You need to move db1 from manual throughput to autoscale throughput by using the Azure CLI. The solution must provide a minimum of 4,000 RU/s and a maximum of 40,000 RU/s.
How should you complete the CLI statements? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:

Box 1: migrate -
The az cosmosdb sql database throughput migrate command migrates the throughput of the SQL database between autoscale and manually provisioned.
Syntax: az cosmosdb sql database throughput migrate
--account-name
--name
--resource-group
--throughput-type {autoscale, manual}
Box 2: update -
The az cosmosdb sql database throughput update command updates the throughput of the SQL database under an Azure Cosmos DB account.
Syntax: az cosmosdb sql database throughput update
--account-name
--name
--resource-group
[--max-throughput]
[--throughput]
Box 3: 4000 -
Specify the throughput.
Parameter --throughput -
The throughput of SQL database (RU/s).
Note: Example migration from standard (manual) provisioned throughput to autoscale: Suppose you have a container with 10,000 RU/s manual provisioned throughput, and 25 GB of storage. When you enable autoscale, the initial autoscale max RU/s will be: 10,000 RU/s, which will scale between 1000 - 10,000 RU/s.
Note 2: Parameter --max-throughput
The maximum throughput resource can scale to (RU/s). Provided when the resource is autoscale enabled. The minimum value can be 4000 (RU/s).
Reference:
https://docs.microsoft.com/en-us/cli/azure/cosmosdb/sql/database/throughput
You need to create a database in an Azure Cosmos DB Core (SQL) API account. The database will contain three containers named coll1, coll2, and coll3. The coll1 container will have unpredictable read and write volumes. The coll2 and coll3 containers will have predictable read and write volumes. The expected maximum throughput for coll1 and coll2 is 50,000 request units per second (RU/s) each.
How should you provision the collection while minimizing costs?
Answer:
B
Manual is best suited for workloads with steady or predictable traffic.
Autoscale workloads is best suited with variable or unpredictable traffic.
Note: Azure Cosmos DB allows you to set provisioned throughput on your databases and containers. There are two types of provisioned throughput, standard
(manual) or autoscale.
Autoscale provisioned throughput in Azure Cosmos DB allows you to scale the throughput (RU/s) of your database or container automatically and instantly. The throughput is scaled based on the usage, without impacting the availability, latency, throughput, or performance of the workload.
The use cases of autoscale include:
* Variable or unpredictable workloads
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/how-to-choose-offer
HOTSPOT -
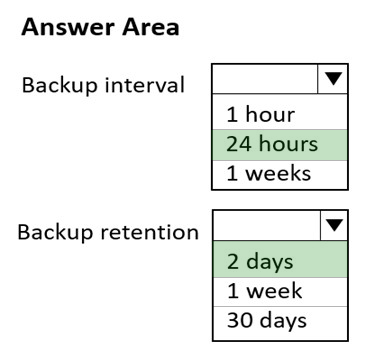
You have a database in an Azure Cosmos DB SQL API Core (SQL) account that is used for development.
The database is modified once per day in a batch process.
You need to ensure that you can restore the database if the last batch process fails. The solution must minimize costs.
How should you configure the backup settings? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area: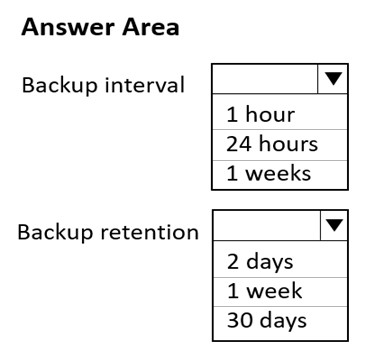
Answer:
HOTSPOT -
You have an Azure Cosmos DB Core (SQL) API account named account1.
You have the Azure virtual networks and subnets shown in the following table.
The vnet1 and vnet2 networks are connected by using a virtual network peer.
The Firewall and virtual network settings for account1 are configured as shown in the exhibit.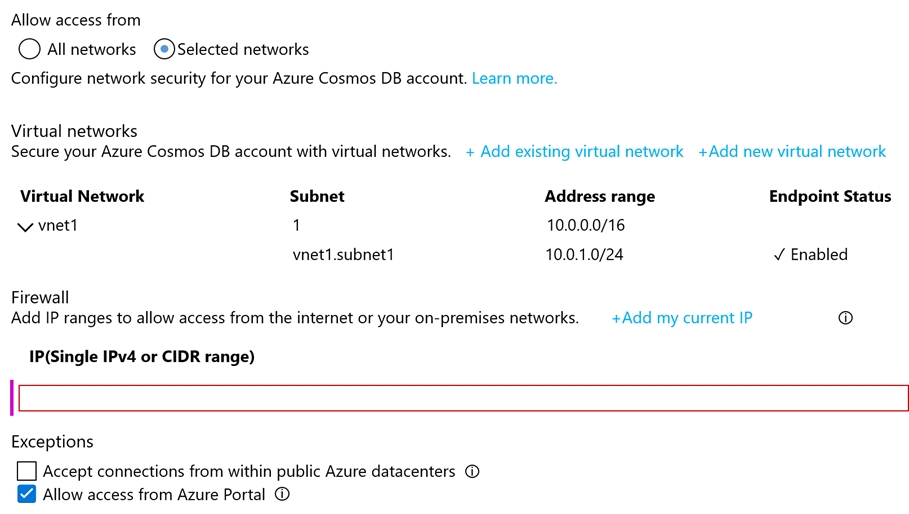
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area: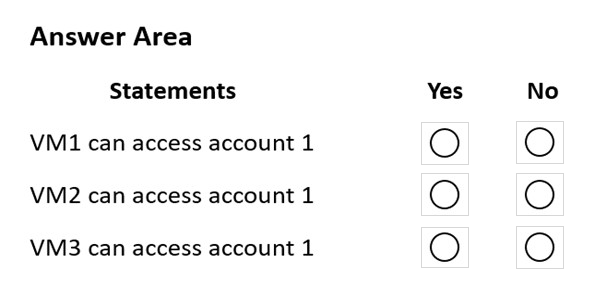
Answer:
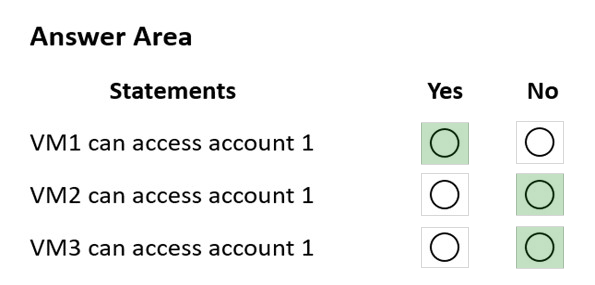
Box 1: Yes -
VM1 is on vnet1.subnet1 which has the Endpoint Status enabled.
Box 2: No -
Only virtual network and their subnets added to Azure Cosmos account have access. Their peered VNets cannot access the account until the subnets within peered virtual networks are added to the account.
Box 3: No -
Only virtual network and their subnets added to Azure Cosmos account have access.
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/how-to-configure-vnet-service-endpoint
You plan to create an Azure Cosmos DB Core (SQL) API account that will use customer-managed keys stored in Azure Key Vault.
You need to configure an access policy in Key Vault to allow Azure Cosmos DB access to the keys.
Which three permissions should you enable in the access policy? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
Answer:
ABG
To Configure customer-managed keys for your Azure Cosmos account with Azure Key Vault:
Add an access policy to your Azure Key Vault instance:
1. From the Azure portal, go to the Azure Key Vault instance that you plan to use to host your encryption keys. Select Access Policies from the left menu:
2. Select + Add Access Policy.
3. Under the Key permissions drop-down menu, select Get, Unwrap Key, and Wrap Key permissions: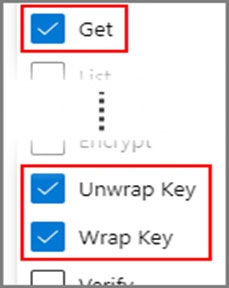
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/how-to-setup-cmk
You need to configure an Apache Kafka instance to ingest data from an Azure Cosmos DB Core (SQL) API account. The data from a container named telemetry must be added to a Kafka topic named iot. The solution must store the data in a compact binary format.
Which three configuration items should you include in the solution? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
Answer:
CDF
C: Avro is binary format, while JSON is text.
F: Kafka Connect for Azure Cosmos DB is a connector to read from and write data to Azure Cosmos DB. The Azure Cosmos DB sink connector allows you to export data from Apache Kafka topics to an Azure Cosmos DB database. The connector polls data from Kafka to write to containers in the database based on the topics subscription.
D: Create the Azure Cosmos DB sink connector in Kafka Connect. The following JSON body defines config for the sink connector.
Extract:
"connector.class": "com.azure.cosmos.kafka.connect.sink.CosmosDBSinkConnector",
"key.converter": "org.apache.kafka.connect.json.AvroConverter"
"connect.cosmos.containers.topicmap": "hotels#kafka"
Incorrect Answers:
B: JSON is plain text.
Note, full example:
{
"name": "cosmosdb-sink-connector",
"config": {
"connector.class": "com.azure.cosmos.kafka.connect.sink.CosmosDBSinkConnector",
"tasks.max": "1",
"topics": [
"hotels"
],
"value.converter": "org.apache.kafka.connect.json.AvroConverter",
"value.converter.schemas.enable": "false",
"key.converter": "org.apache.kafka.connect.json.AvroConverter",
"key.converter.schemas.enable": "false",
"connect.cosmos.connection.endpoint": "https://<cosmosinstance-name>.documents.azure.com:443/",
"connect.cosmos.master.key": "<cosmosdbprimarykey>",
"connect.cosmos.databasename": "kafkaconnect",
"connect.cosmos.containers.topicmap": "hotels#kafka"
}
}
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/sql/kafka-connector-sink https://www.confluent.io/blog/kafka-connect-deep-dive-converters-serialization-explained/
You are implementing an Azure Data Factory data flow that will use an Azure Cosmos DB (SQL API) sink to write a dataset. The data flow will use 2,000 Apache
Spark partitions.
You need to ensure that the ingestion from each Spark partition is balanced to optimize throughput.
Which sink setting should you configure?
Answer:
C
Batch size: An integer that represents how many objects are being written to Cosmos DB collection in each batch. Usually, starting with the default batch size is sufficient. To further tune this value, note:
Cosmos DB limits single request's size to 2MB. The formula is "Request Size = Single Document Size * Batch Size". If you hit error saying "Request size is too large", reduce the batch size value.
The larger the batch size, the better throughput the service can achieve, while make sure you allocate enough RUs to empower your workload.
Incorrect Answers:
A: Throughput: Set an optional value for the number of RUs you'd like to apply to your CosmosDB collection for each execution of this data flow. Minimum is 400.
B: Write throughput budget: An integer that represents the RUs you want to allocate for this Data Flow write operation, out of the total throughput allocated to the collection.
D: Collection action: Determines whether to recreate the destination collection prior to writing.
None: No action will be done to the collection.
Recreate: The collection will get dropped and recreated
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-cosmos-db
You have a container named container1 in an Azure Cosmos DB Core (SQL) API account.
You need to provide a user named User1 with the ability to insert items into container1 by using role-based access control (RBAC). The solution must use the principle of least privilege.
Which roles should you assign to User1?
Answer:
A
Cosmos DB Operator: Can provision Azure Cosmos accounts, databases, and containers. Cannot access any data or use Data Explorer.
Incorrect Answers:
B: DocumentDB Account Contributor can manage Azure Cosmos DB accounts. Azure Cosmos DB is formerly known as DocumentDB.
C: DocumentDB Account Contributor: Can manage Azure Cosmos DB accounts.
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/role-based-access-control
You have an Azure Cosmos DB Core (SQL) API account.
You configure the diagnostic settings to send all log information to a Log Analytics workspace.
You need to identify when the provisioned request units per second (RU/s) for resources within the account were modified.
You write the following query.
AzureDiagnostics -
| where Category == "ControlPlaneRequests"
What should you include in the query?
Answer:
A
The following are the operation names in diagnostic logs for different operations:
RegionAddStart, RegionAddComplete
RegionRemoveStart, RegionRemoveComplete
AccountDeleteStart, AccountDeleteComplete
RegionFailoverStart, RegionFailoverComplete
AccountCreateStart, AccountCreateComplete
*AccountUpdateStart*, AccountUpdateComplete
VirtualNetworkDeleteStart, VirtualNetworkDeleteComplete
DiagnosticLogUpdateStart, DiagnosticLogUpdateComplete
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/audit-control-plane-logs