Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a container named container1 in an Azure Cosmos DB Core (SQL) API account.
You need to make the contents of container1 available as reference data for an Azure Stream Analytics job.
Solution: You create an Azure function that uses Azure Cosmos DB Core (SQL) API change feed as a trigger and Azure event hub as the output.
Does this meet the goal?
Answer:
A
The Azure Cosmos DB change feed is a mechanism to get a continuous and incremental feed of records from an Azure Cosmos container as those records are being created or modified. Change feed support works by listening to container for any changes. It then outputs the sorted list of documents that were changed in the order in which they were modified.
The following diagram represents the data flow and components involved in the solution:
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/sql/changefeed-ecommerce-solution
You have an Azure Cosmos DB Core (SQL) API account.
The change feed is enabled on a container named invoice.
You create an Azure function that has a trigger on the change feed.
What is received by the Azure function?
Answer:
B
Change feed is available for each logical partition key within the container.
The change feed is sorted by the order of modification within each logical partition key value.
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/change-feed
DRAG DROP -
You have an Azure Synapse Analytics workspace named workspace1 that contains a serverless SQL pool.
You have an Azure Table Storage account that stores operational data.
You need to replace the Table storage account with Azure Cosmos DB Core (SQL) API. The solution must meet the following requirements:
✑ Support queries from the serverless SQL pool.
✑ Only pay for analytical compute when running queries.
✑ Ensure that analytical processes do NOT affect operational processes.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place: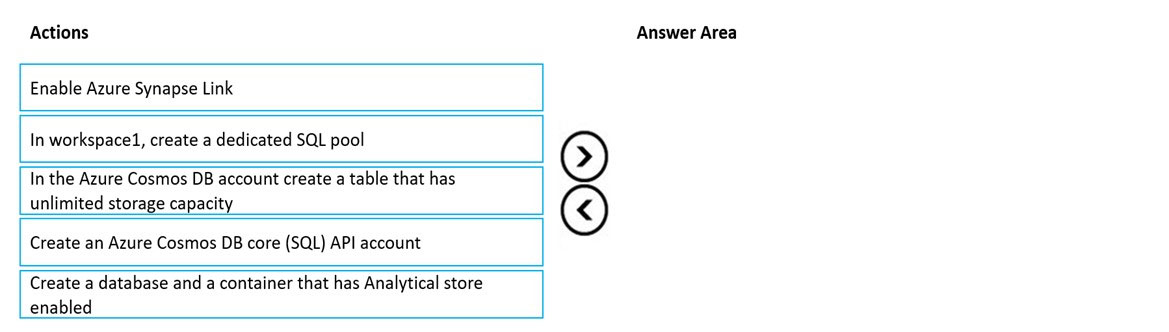
Answer:
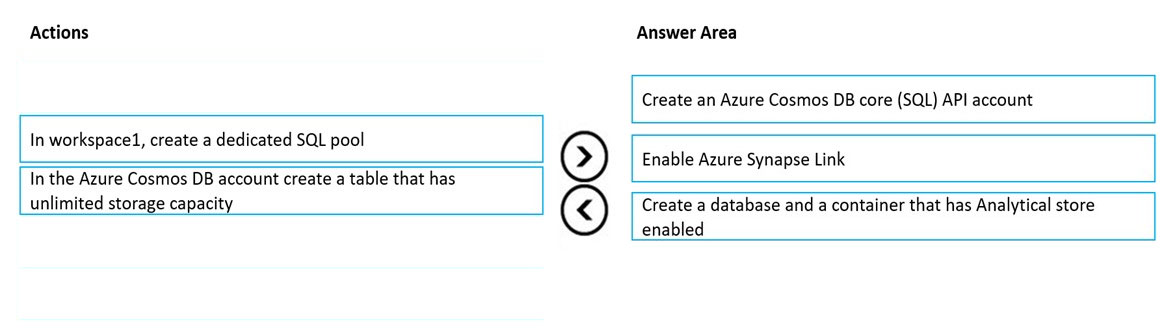
Step 1: Create an Azure Cosmos DB core (SQL) API account
Step 2: Enable Azure Synapse Link
Synapse Link creates a tight seamless integration between Azure Cosmos DB and Azure Synapse Analytics.
Serverless SQL pool allows you to query and analyze data in your Azure Cosmos DB containers that are enabled with Azure Synapse Link. You can analyze data in near real-time without impacting the performance of your transactional workloads.
Step 3: Create a database and a container that has Analytical store enabled
Create an analytical store enabled container
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/configure-synapse-link
You have a database named db1 in an Azure Cosmos DB Core (SQL) API account named account1.
You need to write JSON data to db1 by using Azure Stream Analytics. The solution must minimize costs.
Which should you do before you can use db1 as an output of Stream Analytics?
Answer:
A
Azure Cosmos DB settings for JSON output.
Using Azure Cosmos DB as an output in Stream Analytics generates the following prompt for information.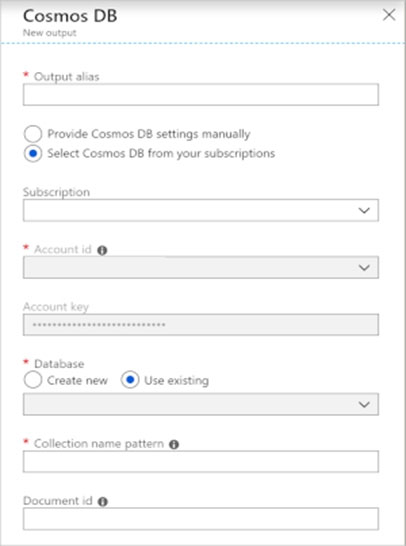
Field: Description -
Output alias: An alias to refer to this output in your Stream Analytics query.
Subscription:The Azure subscription.
Account ID: The name or endpoint URI of the Azure Cosmos DB account.
Etc.
Note: A private endpoint could be used for a VPN connection.
Reference:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-documentdb-output
You have a database named db1 in an Azure Cosmos DB Core (SQL) API account.
You have a third-party application that is exposed through a REST API.
You need to migrate data from the application to a container in db1 on a weekly basis.
What should you use?
Answer:
B
You can use Copy Activity in Azure Data Factory to copy data from and to Azure Cosmos DB (SQL API).
The Azure Cosmos DB (SQL API) connector is supported for the following activities:
Copy activity with supported source/sink matrix
Mapping data flow -
Lookup activity -
Incorrect:
Not A: Azure Migrate provides a centralized hub to assess and migrate on-premises servers, infrastructure, applications, and data to Azure. It assesses on- premises databases and migrate them to Azure SQL Database or to SQL Managed Instance.
Not C: Data Migration Assistant (DMA) enables you to upgrade to a modern data platform by detecting compatibility issues that can impact database functionality on your new version of SQL Server. It recommends performance and reliability improvements for your target environment.
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-cosmos-db
HOTSPOT -
You have an Apache Spark pool in Azure Synapse Analytics that runs the following Python code in a notebook.
For each of the following statements. select Yes if the statement is true. Otherwise. select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:

Box 1: No -
Streaming ג€" Append Output Mode is an outputMode in which only the new rows in the streaming DataFrame/Dataset will be written to the sink.
This is the default mode. Use append as output mode outputMode("append") when you want to output only new rows to the output sink.
Note:
Streaming ג€" Complete Output Mode is an OutputMode in which all the rows in the streaming DataFrame/Dataset will be written to the sink every time there are some updates.
Streaming ג€" Update Output Mode is an outputMode in which only the rows that were updated in the streaming DataFrame/Dataset will be written to the sink every time there are some updates.
Box 2: No -
Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. You can express your streaming computation the same way you would express a batch computation on static data. The Spark SQL engine will take care of running it incrementally and continuously and updating the final result as streaming data continues to arrive.
Box 3: Yes -
Synapse Apache Spark also allows you to ingest data into Azure Cosmos DB. It is important to note that data is always ingested into Azure Cosmos DB containers through the transactional store. When Synapse Link is enabled, any new inserts, updates, and deletes are then automatically synced to the analytical store.
Reference:
https://sparkbyexamples.com/spark/spark-streaming-outputmode/ https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html https://docs.microsoft.com/en-us/azure/synapse-analytics/synapse-link/how-to-query-analytical-store-spark
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a container named container1 in an Azure Cosmos DB Core (SQL) API account.
You need to make the contents of container1 available as reference data for an Azure Stream Analytics job.
Solution: You create an Azure function to copy data to another Azure Cosmos DB Core (SQL) API container.
Does this meet the goal?
Answer:
B
Instead: Create an Azure function that uses Azure Cosmos DB Core (SQL) API change feed as a trigger and Azure event hub as the output.
Note: The Azure Cosmos DB change feed is a mechanism to get a continuous and incremental feed of records from an Azure Cosmos container as those records are being created or modified. Change feed support works by listening to container for any changes. It then outputs the sorted list of documents that were changed in the order in which they were modified.
The following diagram represents the data flow and components involved in the solution:
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/sql/changefeed-ecommerce-solution
HOTSPOT -
You have the indexing policy shown in the following exhibit.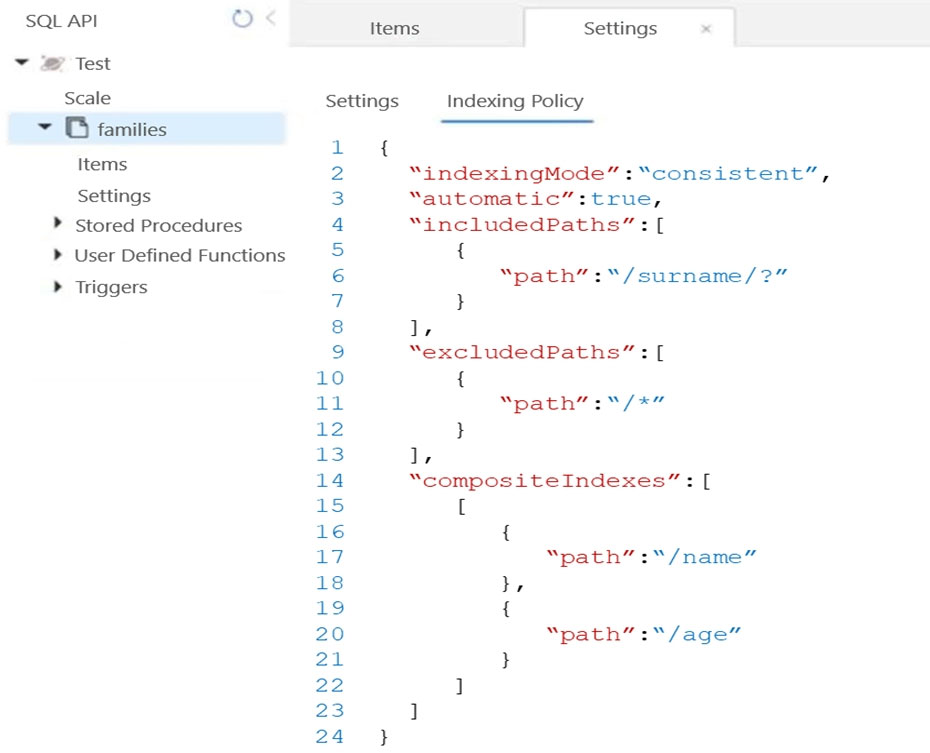
Use the drop-down menus to select the answer choice that answers each question based on the information presented in the graphic.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:

Box 1: ORDER BY c.name DESC, c.age DESC
Queries that have an ORDER BY clause with two or more properties require a composite index.
The following considerations are used when using composite indexes for queries with an ORDER BY clause with two or more properties:
✑ If the composite index paths do not match the sequence of the properties in the ORDER BY clause, then the composite index can't support the query.
✑ The order of composite index paths (ascending or descending) should also match the order in the ORDER BY clause.
✑ The composite index also supports an ORDER BY clause with the opposite order on all paths.
Box 2: At the same time as the item creation
Azure Cosmos DB supports two indexing modes:
✑ Consistent: The index is updated synchronously as you create, update or delete items. This means that the consistency of your read queries will be the consistency configured for the account.
✑ None: Indexing is disabled on the container.
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/index-policy
You have a container named container1 in an Azure Cosmos DB Core (SQL) API account. Upserts of items in container1 occur every three seconds.
You have an Azure Functions app named function1 that is supposed to run whenever items are inserted or replaced in container1.
You discover that function1 runs, but not on every upsert.
You need to ensure that function1 processes each upsert within one second of the upsert.
Which property should you change in the Function.json file of function1?
Answer:
D
With an upsert operation we can either insert or update an existing record at the same time.
FeedPollDelay: The time (in milliseconds) for the delay between polling a partition for new changes on the feed, after all current changes are drained. Default is
5,000 milliseconds, or 5 seconds.
Incorrect Answers:
A: checkpointInterval: When set, it defines, in milliseconds, the interval between lease checkpoints. Default is always after each Function call.
C: maxItemsPerInvocation: When set, this property sets the maximum number of items received per Function call. If operations in the monitored collection are performed through stored procedures, transaction scope is preserved when reading items from the change feed. As a result, the number of items received could be higher than the specified value so that the items changed by the same transaction are returned as part of one atomic batch.
Reference:
https://docs.microsoft.com/en-us/azure/azure-functions/functions-bindings-cosmosdb-v2-trigger
HOTSPOT -
You have a container named container1 in an Azure Cosmos DB Core (SQL) API account.
The following is a sample of a document in container1.
The container1 container has the following indexing policy.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:

Box 1: Yes -
"path": "/*" is in includePaths.
Include the root path to selectively exclude paths that don't need to be indexed. This is the recommended approach as it lets Azure Cosmos DB proactively index any new property that may be added to your model.
Box 2: No -
"path": "/firstName/?" is in excludePaths.
Box 3: Yes -
"path": "/address/city/?" is in includePaths
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/index-policy