DRAG DROP -
You are developing a microservices solution. You plan to deploy the solution to a multinode Azure Kubernetes Service (AKS) cluster.
You need to deploy a solution that includes the following features:
✑ reverse proxy capabilities
✑ configurable traffic routing
✑ TLS termination with a custom certificate
Which components should you use? To answer, drag the appropriate components to the correct requirements. Each component may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
Answer:
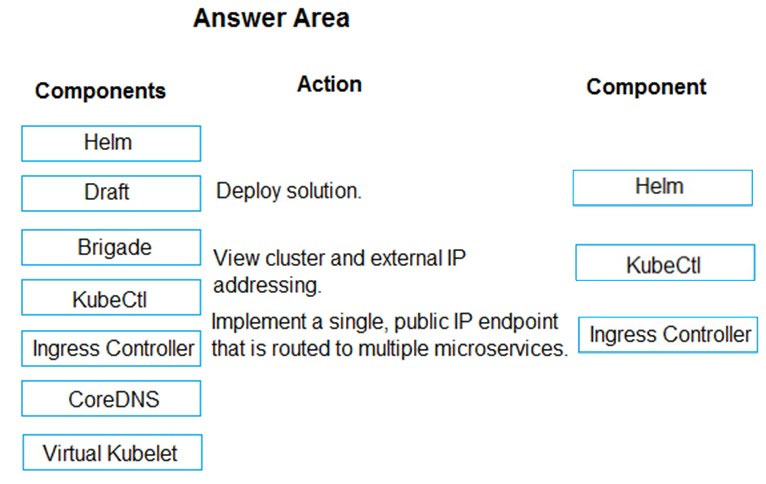
Box 1: Helm -
To create the ingress controller, use Helm to install nginx-ingress.
Box 2: kubectl -
To find the cluster IP address of a Kubernetes pod, use the kubectl get pod command on your local machine, with the option -o wide .
Box 3: Ingress Controller -
An ingress controller is a piece of software that provides reverse proxy, configurable traffic routing, and TLS termination for Kubernetes services. Kubernetes ingress resources are used to configure the ingress rules and routes for individual Kubernetes services.
Incorrect Answers:
Virtual Kubelet: Virtual Kubelet is an open-source Kubernetes kubelet implementation that masquerades as a kubelet. This allows Kubernetes nodes to be backed by Virtual Kubelet providers such as serverless cloud container platforms.
CoreDNS: CoreDNS is a flexible, extensible DNS server that can serve as the Kubernetes cluster DNS. Like Kubernetes, the CoreDNS project is hosted by the
CNCF.
Reference:
https://docs.microsoft.com/bs-cyrl-ba/azure/aks/ingress-basic https://www.digitalocean.com/community/tutorials/how-to-inspect-kubernetes-networking
DRAG DROP -
You are implementing an order processing system. A point of sale application publishes orders to topics in an Azure Service Bus queue. The Label property for the topic includes the following data:
The system has the following requirements for subscriptions:
You need to implement filtering and maximize throughput while evaluating filters.
Which filter types should you implement? To answer, drag the appropriate filter types to the correct subscriptions. Each filter type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
Answer:

FutureOrders: SQLFilter -
HighPriortyOrders: CorrelationFilter
CorrelationID only -
InternationalOrders: SQLFilter -
Country NOT USA requires an SQL Filter
HighQuantityOrders: SQLFilter -
Need to use relational operators so an SQL Filter is needed.
AllOrders: No Filter -
SQL Filter: SQL Filters - A SqlFilter holds a SQL-like conditional expression that is evaluated in the broker against the arriving messages' user-defined properties and system properties. All system properties must be prefixed with sys. in the conditional expression. The SQL-language subset for filter conditions tests for the existence of properties (EXISTS), as well as for null-values (IS NULL), logical NOT/AND/OR, relational operators, simple numeric arithmetic, and simple text pattern matching with LIKE.
Correlation Filters - A CorrelationFilter holds a set of conditions that are matched against one or more of an arriving message's user and system properties. A common use is to match against the CorrelationId property, but the application can also choose to match against ContentType, Label, MessageId, ReplyTo,
ReplyToSessionId, SessionId, To, and any user-defined properties. A match exists when an arriving message's value for a property is equal to the value specified in the correlation filter. For string expressions, the comparison is case-sensitive. When specifying multiple match properties, the filter combines them as a logical
AND condition, meaning for the filter to match, all conditions must match.
Boolean filters - The TrueFilter and FalseFilter either cause all arriving messages (true) or none of the arriving messages (false) to be selected for the subscription.
Reference:
https://docs.microsoft.com/en-us/azure/service-bus-messaging/topic-filters
DRAG DROP -
Your company has several websites that use a company logo image. You use Azure Content Delivery Network (CDN) to store the static image.
You need to determine the correct process of how the CDN and the Point of Presence (POP) server will distribute the image and list the items in the correct order.
In which order do the actions occur? To answer, move all actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
Answer:

Step 1: A user requests the image..
A user requests a file (also called an asset) by using a URL with a special domain name, such as <endpoint name>.azureedge.net. This name can be an endpoint hostname or a custom domain. The DNS routes the request to the best performing POP location, which is usually the POP that is geographically closest to the user.
Step 2: If no edge servers in the POP have the..
If no edge servers in the POP have the file in their cache, the POP requests the file from the origin server. The origin server can be an Azure Web App, Azure
Cloud Service, Azure Storage account, or any publicly accessible web server.
Step 3: The origin server returns the..
The origin server returns the file to an edge server in the POP.
An edge server in the POP caches the file and returns the file to the original requestor (Alice). The file remains cached on the edge server in the POP until the time-to-live (TTL) specified by its HTTP headers expires. If the origin server didn't specify a TTL, the default TTL is seven days.
Step 4: Subsequent requests for..
Additional users can then request the same file by using the same URL that the original user used, and can also be directed to the same POP.
If the TTL for the file hasn't expired, the POP edge server returns the file directly from the cache. This process results in a faster, more responsive user experience.
Reference:
https://docs.microsoft.com/en-us/azure/cdn/cdn-overview
You are developing an Azure Cosmos DB solution by using the Azure Cosmos DB SQL API. The data includes millions of documents. Each document may contain hundreds of properties.
The properties of the documents do not contain distinct values for partitioning. Azure Cosmos DB must scale individual containers in the database to meet the performance needs of the application by spreading the workload evenly across all partitions over time.
You need to select a partition key.
Which two partition keys can you use? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
Answer:
DE
You can form a partition key by concatenating multiple property values into a single artificial partitionKey property. These keys are referred to as synthetic keys.
Another possible strategy to distribute the workload more evenly is to append a random number at the end of the partition key value. When you distribute items in this way, you can perform parallel write operations across partitions.
Note: It's the best practice to have a partition key with many distinct values, such as hundreds or thousands. The goal is to distribute your data and workload evenly across the items associated with these partition key values. If such a property doesn't exist in your data, you can construct a synthetic partition key.
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/synthetic-partition-keys
HOTSPOT -
You are developing an Azure-hosted e-commerce web application. The application will use Azure Cosmos DB to store sales orders. You are using the latest SDK to manage the sales orders in the database.
You create a new Azure Cosmos DB instance. You include a valid endpoint and valid authorization key to an appSettings.json file in the code project.
You are evaluating the following application code: (Line number are included for reference only.)
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:

Box 1: Yes -
The createDatabaseIfNotExistsAsync method checks if a database exists, and if it doesn't, create it.
The Database.CreateContainerAsync method creates a container as an asynchronous operation in the Azure Cosmos service.
Box 2: Yes -
The CosmosContainer.CreateItemAsync method creates an item as an asynchronous operation in the Azure Cosmos service.
Box 3: Yes -
Reference:
https://docs.microsoft.com/en-us/dotnet/api/microsoft.azure.cosmos.cosmosclient.createdatabaseifnotexistsasync https://docs.microsoft.com/en-us/dotnet/api/microsoft.azure.cosmos.database.createcontainerasync https://docs.microsoft.com/en-us/dotnet/api/azure.cosmos.cosmoscontainer.createitemasync
DRAG DROP -
You develop an Azure solution that uses Cosmos DB.
The current Cosmos DB container must be replicated and must use a partition key that is optimized for queries.
You need to implement a change feed processor solution.
Which change feed processor components should you use? To answer, drag the appropriate components to the correct requirements. Each component may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view the content.
NOTE: Each correct selection is worth one point.
Select and Place:
Answer:

Box 1: The monitored container -
The monitored container has the data from which the change feed is generated. Any inserts and updates to the monitored container are reflected in the change feed of the container.
Box 2: The lease container -
The lease container acts as a state storage and coordinates processing the change feed across multiple workers. The lease container can be stored in the same account as the monitored container or in a separate account.
Box 3: The host: A host is an application instance that uses the change feed processor to listen for changes. Multiple instances with the same lease configuration can run in parallel, but each instance should have a different instance name.
Box 4: The delegate -
The delegate is the code that defines what you, the developer, want to do with each batch of changes that the change feed processor reads.
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/change-feed-processor
HOTSPOT -
You are developing a web application that will use Azure Storage. Older data will be less frequently used than more recent data.
You need to configure data storage for the application. You have the following requirements:
✑ Retain copies of data for five years.
✑ Minimize costs associated with storing data that is over one year old.
✑ Implement Zone Redundant Storage for application data.
What should you do? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area: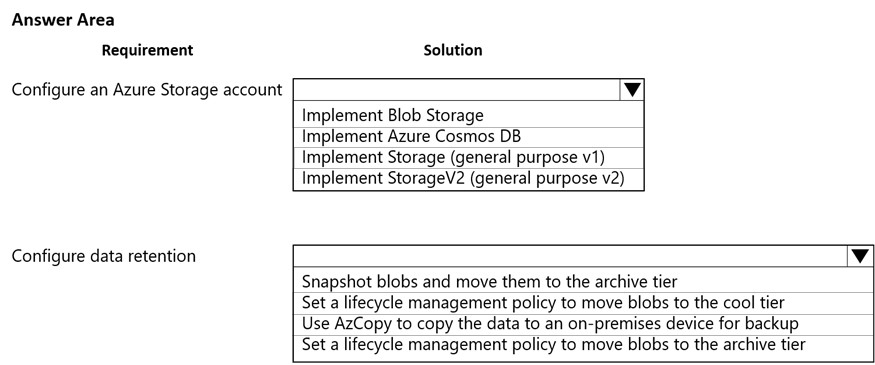
Answer:

Reference:
https://docs.microsoft.com/en-us/azure/storage/blobs/storage-blob-storage-tiers https://docs.microsoft.com/en-us/azure/storage/common/storage-redundancy?toc=/azure/storage/blobs/toc.json
HOTSPOT -
A company develops a series of mobile games. All games use a single leaderboard service.
You have the following requirements:
✑ Code must be scalable and allow for growth.
✑ Each record must consist of a playerId, gameId, score, and time played.
✑ When users reach a new high score, the system will save the new score using the SaveScore function below.
Each game is assigned an Id based on the series title.
You plan to store customer information in Azure Cosmos DB. The following data already exists in the database:
You develop the following code to save scores in the data store. (Line numbers are included for reference only.)
You develop the following code to query the database. (Line numbers are included for reference only.)
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:

Box 1: Yes -
Create a table.
A CloudTableClient object lets you get reference objects for tables and entities. The following code creates a CloudTableClient object and uses it to create a new
CloudTable object, which represents a table
// Retrieve storage account from connection-string.
CloudStorageAccount storageAccount =
CloudStorageAccount.parse(storageConnectionString);
// Create the table client.
CloudTableClient tableClient = storageAccount.createCloudTableClient();
// Create the table if it doesn't exist.
String tableName = "people";
CloudTable cloudTable = tableClient.getTableReference(tableName); cloudTable.createIfNotExists();
Box 2: No -
New records are inserted with TableOperation.insert. Old records are not updated.
To update old records TableOperation.insertOrReplace should be used instead.
Box 3: No -
Box 4: Yes -
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/table-storage-how-to-use-java
You develop and deploy a web application to Azure App Service. The application accesses data stored in an Azure Storage account. The account contains several containers with several blobs with large amounts of data. You deploy all Azure resources to a single region.
You need to move the Azure Storage account to the new region. You must copy all data to the new region.
What should you do first?
Answer:
A
To move a storage account, create a copy of your storage account in another region. Then, move your data to that account by using AzCopy, or another tool of your choice and finally, delete the resources in the source region.
To get started, export, and then modify a Resource Manager template.
Reference:
https://docs.microsoft.com/en-us/azure/storage/common/storage-account-move?tabs=azure-portal
HOTSPOT -
You are developing an application to collect the following telemetry data for delivery drivers: first name, last name, package count, item id, and current location coordinates. The app will store the data in Azure Cosmos DB.
You need to configure Azure Cosmos DB to query the data.
Which values should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:

Box 1: Core (SQL)
Core(SQL) API stores data in document format. It offers the best end-to-end experience as we have full control over the interface, service, and the SDK client libraries. SQL API supports analytics and offers performance isolation between operational and analytical workloads.
Box 2: item id -
item id is a unique identifier and is suitable for the partition key.
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/choose-api
https://docs.microsoft.com/en-us/azure/cosmos-db/partitioning-overview