HOTSPOT -
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:

Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/how-to-designer-python https://docs.microsoft.com/en-us/azure/machine-learning/concept-automated-ml
A medical research project uses a large anonymized dataset of brain scan images that are categorized into predefined brain haemorrhage types.
You need to use machine learning to support early detection of the different brain haemorrhage types in the images before the images are reviewed by a person.
This is an example of which type of machine learning?
Answer:
C
Reference:
https://docs.microsoft.com/en-us/learn/modules/create-classification-model-azure-machine-learning-designer/introduction
When training a model, why should you randomly split the rows into separate subsets?
Answer:
C
You are evaluating whether to use a basic workspace or an enterprise workspace in Azure Machine Learning.
What are two tasks that require an enterprise workspace? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
Answer:
AC
Note: Enterprise workspaces are no longer available as of September 2020. The basic workspace now has all the functionality of the enterprise workspace.
Reference:
https://www.azure.cn/en-us/pricing/details/machine-learning/
https://docs.microsoft.com/en-us/azure/machine-learning/concept-workspace
You need to predict the income range of a given customer by using the following dataset.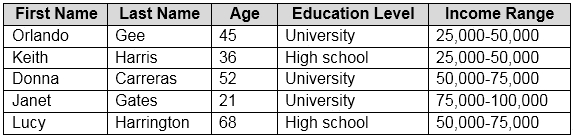
Which two fields should you use as features? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
Answer:
AC
First Name, Last Name, Age and Education Level are features. Income range is a label (what you want to predict). First Name and Last Name are irrelevant in that they have no bearing on income. Age and Education level are the features you should use.
You are building a tool that will process images from retail stores and identify the products of competitors.
The solution will use a custom model.
Which Azure Cognitive Services service should you use?
Answer:
A
Reference:
https://docs.microsoft.com/en-us/azure/cognitive-services/custom-vision-service/overview
HOTSPOT -
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:

Clustering is a machine learning task that is used to group instances of data into clusters that contain similar characteristics. Clustering can also be used to identify relationships in a dataset
Regression is a machine learning task that is used to predict the value of the label from a set of related features.
Reference:
https://docs.microsoft.com/en-us/dotnet/machine-learning/resources/tasks
HOTSPOT -
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:

Box 1: No -
The validation dataset is different from the test dataset that is held back from the training of the model.
Box 2: Yes -
A validation dataset is a sample of data that is used to give an estimate of model skill while tuning model's hyperparameters.
Box 3: No -
The Test Dataset, not the validation set, used for this. The Test Dataset is a sample of data used to provide an unbiased evaluation of a final model fit on the training dataset.
Reference:
https://machinelearningmastery.com/difference-test-validation-datasets/
What are two metrics that you can use to evaluate a regression model? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
Answer:
AC
A: R-squared (R2), or Coefficient of determination represents the predictive power of the model as a value between -inf and 1.00. 1.00 means there is a perfect fit, and the fit can be arbitrarily poor so the scores can be negative.
C: RMS-loss or Root Mean Squared Error (RMSE) (also called Root Mean Square Deviation, RMSD), measures the difference between values predicted by a model and the values observed from the environment that is being modeled.
Incorrect Answers:
B: F1 score also known as balanced F-score or F-measure is used to evaluate a classification model.
D: aucROC or area under the curve (AUC) is used to evaluate a classification model.
Reference:
https://docs.microsoft.com/en-us/dotnet/machine-learning/resources/metrics
HOTSPOT -
To complete the sentence, select the appropriate option in the answer area.
Hot Area:
Answer:

Regression is a machine learning task that is used to predict the value of the label from a set of related features.
Reference:
https://docs.microsoft.com/en-us/dotnet/machine-learning/resources/tasks