HOTSPOT -
You are building an app that will enable users to upload images. The solution must meet the following requirements:
* Automatically suggest alt text for the images.
* Detect inappropriate images and block them.
* Minimize development effort.
You need to recommend a computer vision endpoint for each requirement.
What should you recommend? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area: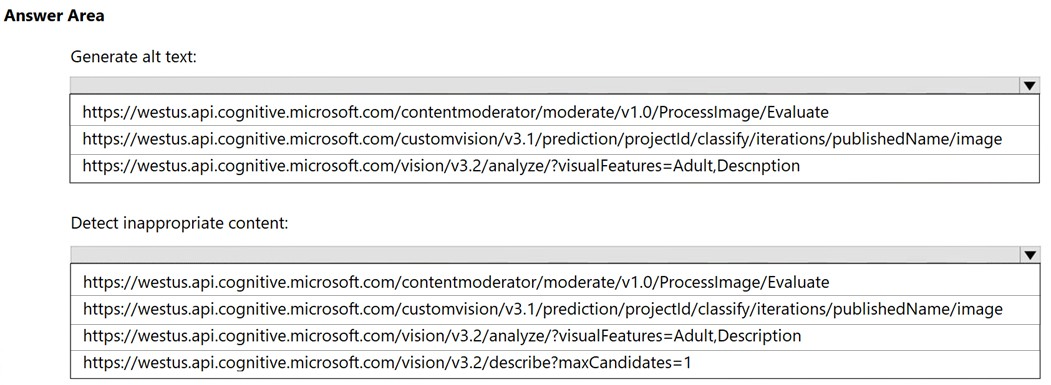
Answer:
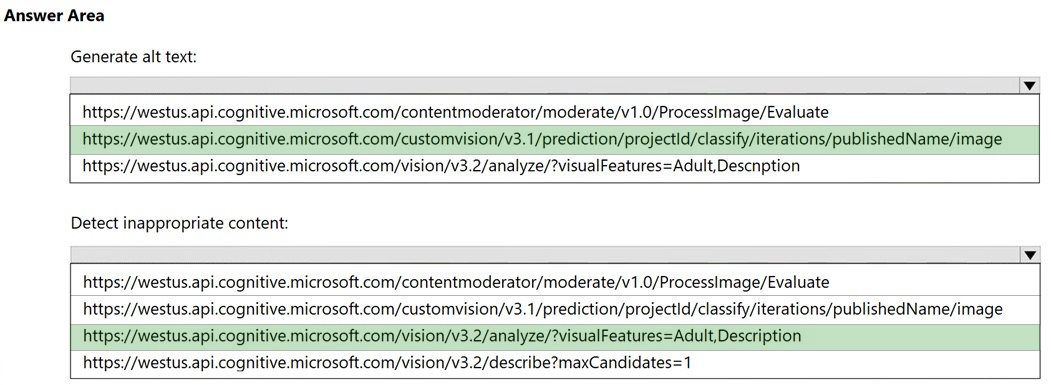
Box 1: https://westus.api.cognitive.microsoft.com/customvision/v3.1/prediction/projectid/classify/iterations/publishName/image
Box 2: https://westus.api.cognitive.microsoft.com/vision/v3.2/analyze/?visualFeatures=Adult,Description
Computer Vision can detect adult material in images so that developers can restrict the display of these images in their software. Content flags are applied with a score between zero and one so developers can interpret the results according to their own preferences.
You can detect adult content with the Analyze Image API. When you add the value of Adult to the visualFeatures query parameter
Incorrect:
Use the Image Moderation API in Azure Content Moderator to scan image content. The moderation job scans your content for profanity, and compares it against custom and shared blocklists.
Reference:
https://docs.microsoft.com/en-us/azure/cognitive-services/computer-vision/concept-detecting-adult-content https://docs.microsoft.com/en-us/azure/cognitive-services/content-moderator/try-image-api https://docs.microsoft.com/en-us/legal/cognitive-services/custom-vision/custom-vision-cvs-transparency-note
You need to build a solution that will use optical character recognition (OCR) to scan sensitive documents by using the Computer Vision API. The solution must
NOT be deployed to the public cloud.
What should you do?
Answer:
B
One option to manage your Computer Vision containers on-premises is to use Kubernetes and Helm.
Three primary parameters for all Cognitive Services containers are required. The Microsoft Software License Terms must be present with a value of accept. An
Endpoint URI and API key are also needed.
Incorrect:
Not D: This Computer Vision endpoint would be available for the public, unless it is secured.
Reference:
https://docs.microsoft.com/en-us/azure/cognitive-services/computer-vision/deploy-computer-vision-on-premises
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You build a language model by using a Language Understanding service. The language model is used to search for information on a contact list by using an intent named FindContact.
A conversational expert provides you with the following list of phrases to use for training.
✑ Find contacts in London.
✑ Who do I know in Seattle?
✑ Search for contacts in Ukraine.
You need to implement the phrase list in Language Understanding.
Solution: You create a new pattern in the FindContact intent.
Does this meet the goal?
Answer:
B
Instead use a new intent for location.
Note: An intent represents a task or action the user wants to perform. It is a purpose or goal expressed in a user's utterance.
Define a set of intents that corresponds to actions users want to take in your application.
Reference:
https://docs.microsoft.com/en-us/azure/cognitive-services/luis/luis-concept-intent
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You develop an application to identify species of flowers by training a Custom Vision model.
You receive images of new flower species.
You need to add the new images to the classifier.
Solution: You add the new images, and then use the Smart Labeler tool.
Does this meet the goal?
Answer:
B
The model need to be extended and retrained.
Note: Smart Labeler to generate suggested tags for images. This lets you label a large number of images more quickly when training a Custom Vision model.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You develop an application to identify species of flowers by training a Custom Vision model.
You receive images of new flower species.
You need to add the new images to the classifier.
Solution: You add the new images and labels to the existing model. You retrain the model, and then publish the model.
Does this meet the goal?
Answer:
A
The model needs to be extended and retrained.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You develop an application to identify species of flowers by training a Custom Vision model.
You receive images of new flower species.
You need to add the new images to the classifier.
Solution: You create a new model, and then upload the new images and labels.
Does this meet the goal?
Answer:
B
The model needs to be extended and retrained.
HOTSPOT -
You are developing a service that records lectures given in English (United Kingdom).
You have a method named AppendToTranscriptFile that takes translated text and a language identifier.
You need to develop code that will provide transcripts of the lectures to attendees in their respective language. The supported languages are English, French,
Spanish, and German.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area: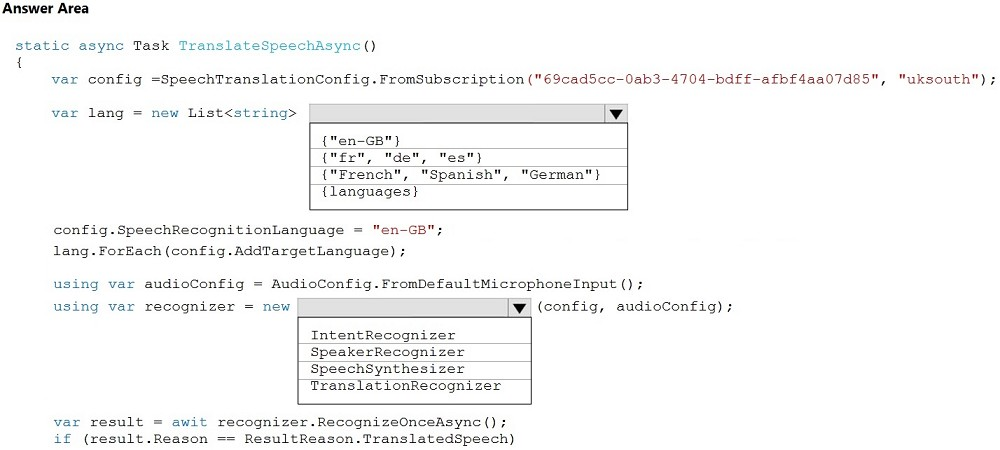
Answer:
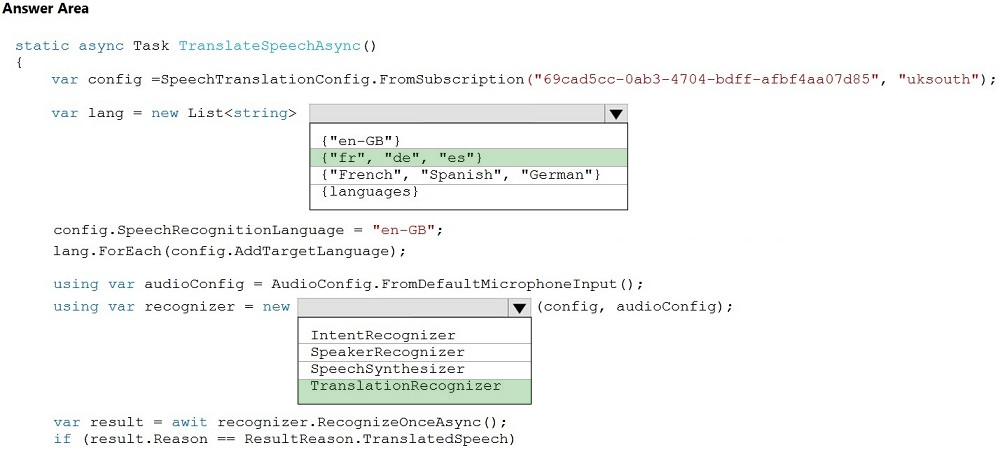
Box 1: {"fr", "de", "es"}
A common task of speech translation is to specify target translation languages, at least one is required but multiples are supported. The following code snippet sets both French and German as translation language targets. static async Task TranslateSpeechAsync()
{
var translationConfig =
SpeechTranslationConfig.FromSubscription(SPEECH__SUBSCRIPTION__KEY, SPEECH__SERVICE__REGION); translationConfig.SpeechRecognitionLanguage = "it-IT";
// Translate to languages. See, https://aka.ms/speech/sttt-languages translationConfig.AddTargetLanguage("fr"); translationConfig.AddTargetLanguage("de");
}
Box 2: TranslationRecognizer -
After you've created a SpeechTranslationConfig, the next step is to initialize a TranslationRecognizer.
Example code:
static async Task TranslateSpeechAsync()
{
var translationConfig =
SpeechTranslationConfig.FromSubscription(SPEECH__SUBSCRIPTION__KEY, SPEECH__SERVICE__REGION); var fromLanguage = "en-US"; var toLanguages = new List<string> { "it", "fr", "de" }; translationConfig.SpeechRecognitionLanguage = fromLanguage; toLanguages.ForEach(translationConfig.AddTargetLanguage); using var recognizer = new TranslationRecognizer(translationConfig);
}
DRAG DROP -
You train a Custom Vision model used in a mobile app.
You receive 1,000 new images that do not have any associated data.
You need to use the images to retrain the model. The solution must minimize how long it takes to retrain the model.
Which three actions should you perform in the Custom Vision portal? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
Answer:
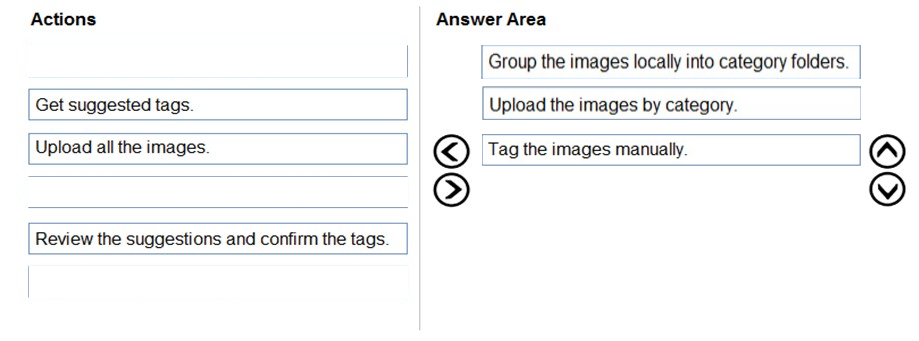
Reference:
https://docs.microsoft.com/en-us/azure/cognitive-services/custom-vision-service/getting-started-build-a-classifier
You are building a Conversational Language Understanding model for an e-commerce chatbot. Users can speak or type their billing address when prompted by the chatbot.
You need to construct an entity to capture billing addresses.
Which entity type should you use?
Answer:
B
Reference:
https://docs.microsoft.com/en-us/azure/cognitive-services/luis/luis-concept-entity-types
You are building an Azure WebJob that will create knowledge bases from an array of URLs.
You instantiate a QnAMakerClient object that has the relevant API keys and assign the object to a variable named client.
You need to develop a method to create the knowledge bases.
Which two actions should you include in the method? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
Answer:
AC
Reference:
https://docs.microsoft.com/en-us/rest/api/cognitiveservices-qnamaker/qnamaker4.0/knowledgebase/create