A company that analyzes the stock market has two offices: one in the us-east-1 Region and another in the eu-west-2 Region. The company wants to implement an AWS database solution that can provide fast and accurate updates.
The office in eu-west-2 has dashboards with complex analytical queries to display the data. The company will use these dashboards to make buying decisions, so the dashboards must have access to the application data in less than 1 second.
Which solution meets these requirements and provides the MOST up-to-date dashboard?
C
A company is running its customer feedback application on Amazon Aurora MySQL. The company runs a report every day to extract customer feedback, and a team reads the feedback to determine if the customer comments are positive or negative. It sometimes takes days before the company can contact unhappy customers and take corrective measures. The company wants to use machine learning to automate this workflow.
Which solution meets this requirement with the LEAST amount of effort?
C
Amazon Comprehend is a natural-language processing (NLP) service that uses machine learning to uncover valuable insights and connections in text.
Reference:
https://aws.amazon.com/comprehend/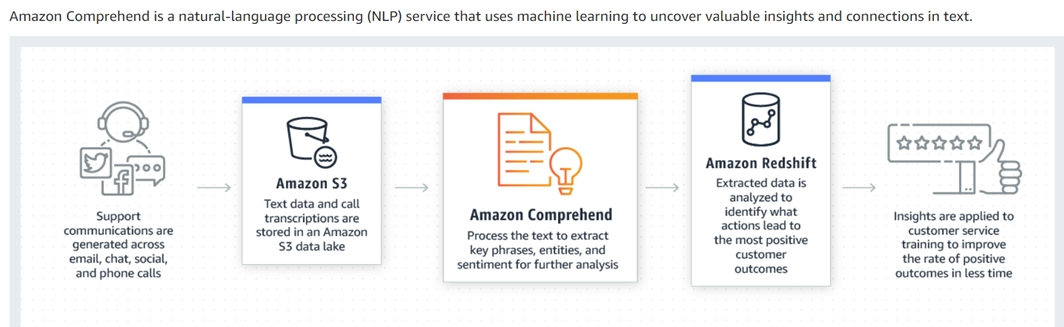
A bank plans to use an Amazon RDS for MySQL DB instance. The database should support read-intensive traffic with very few repeated queries.
Which solution meets these requirements?
D
Reference -
https://cloudbasic.net/aws/rds/sqlserver/managing-rds-read-replicas-on-aws/
A database specialist has a fleet of Amazon RDS DB instances that use the default DB parameter group. The database specialist needs to associate a custom parameter group with some of the DB instances.
After the database specialist makes this change, when will the instances be assigned to this new parameter group?
C
To apply the latest parameter changes to that DB instance, manually reboot the DB instance.
Reference:
https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_WorkingWithParamGroups.html
A company is planning on migrating a 500-GB database from Oracle to Amazon Aurora PostgreSQL using the AWS Schema Conversion Tool (AWS SCT) and
AWS DMS. The database does not have any stored procedures to migrate but has some tables that are large or partitioned. The application is critical for business so a migration with minimal downtime is preferred.
Which combination of steps should a database specialist take to accelerate the migration process? (Choose three.)
BF
Reference:
https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Tasks.CustomizingTasks.TaskSettings.FullLoad.html https://aws.amazon.com/blogs/database/continuous-database-replication-using-aws-dms-to-migrate-from-oracle-to-amazon-aurora/
https://aws.amazon.com/blogs/database/continuous-database-replication-using-aws-dms-to-migrate-from-oracle-to-amazon-aurora/
A company is migrating an IBM Informix database to a Multi-AZ deployment of Amazon RDS for SQL Server with Always On Availability Groups (AGs). SQL
Server Agent jobs on the Always On AG listener run at 5-minute intervals to synchronize data between the Informix database and the SQL Server database. Users experience hours of stale data after a successful failover to the secondary node with minimal latency.
What should a database specialist do to ensure that users see recent data after a failover?
C
After a failover, client applications that need to access the primary databases must connect to the new primary replica. Also, if the new secondary replica is configured to allow read-only access, read-only client applications can connect to it.
Reference:
https://docs.microsoft.com/en-us/sql/database-engine/availability-groups/windows/failover-and-failover-modes-always-on-availability-groups?view=sql- server-ver15
A database specialist needs to configure an Amazon RDS for MySQL DB instance to close non-interactive connections that are inactive after 900 seconds.
What should the database specialist do to accomplish this task?
B
If we set the wait_timeout variable for a session, it will valid only for a particular session. But when we set the wait_timeout variable globally it will valid for all the sessions.
Reference:
https://dilsichandrasena.medium.com/changing-mysql-wait-timeout-variable-f16ebed1efce
A company is running its production databases in a 3 TB Amazon Aurora MySQL DB cluster. The DB cluster is deployed to the us-east-1 Region. For disaster recovery (DR) purposes, the company's database specialist needs to make the DB cluster rapidly available in another AWS Region to cover the production load with an RTO of less than 2 hours.
What is the MOST operationally efficient solution to meet these requirements?
B
Reference:
https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_ReadRepl.html
A company has an on-premises SQL Server database. The users access the database using Active Directory authentication. The company successfully migrated its database to Amazon RDS for SQL Server. However, the company is concerned about user authentication in the AWS Cloud environment.
Which solution should a database specialist provide for the user to authenticate?
B
Reference:
https://docs.aws.amazon.com/directoryservice/latest/admin-guide/ms_ad_tutorial_setup_trust.html
A company uses an Amazon Redshift cluster to run its analytical workloads. Corporate policy requires that the company's data be encrypted at rest with customer managed keys. The company's disaster recovery plan requires that backups of the cluster be copied into another AWS Region on a regular basis.
How should a database specialist automate the process of backing up the cluster data in compliance with these policies?
A
Reference:
https://docs.aws.amazon.com/kms/latest/developerguide/kms-dg.pdf